


Roadmap: Voice AI
Voice AI isn’t just an upgrade to software’s UI — it's transforming how businesses and customers connect.

Imagine this: Your flight has just been canceled, and you are standing at the airport gate, trying to contact your airline’s customer service line, but they’ve informed you that “due to increased call volume, call waiting times are longer than usual.” You’re stuck in an endless maze of automated menus, repeating “speak to a representative” after every option fails to address what you need. When you finally connect with a person, they transfer you, forcing you to explain your situation all over again to someone else. Meanwhile, the minutes are ticking by. You’re no closer to rebooking your flight or resolving the issue, and the prospect of staying at an overnight airport hotel feels inevitable. This is a stressful, expensive, and all-too-familiar travel nightmare millions experience.
Now picture this: You call the airline, and instead of a long hold, a robotic voice, or a string of options, you’re greeted by an AI that instantly understands your situation. It recognizes that you’ve missed your flight, suggests the best alternatives based on your preferences, and handles rebooking. This is just one example of the promise of voice AI technology applied to a problem we all know — and like most applications of transformative technologies, we’ve yet to discover the most compelling use cases because they weren’t possible before AI.
Voice AI solutions can finally engage in human-like conversations.
With advancements across all layers of the voice technology stack, voice AI solutions can finally engage in human-like conversations, personalize the customer experience, and scale infinitely to meet spikes in demand any time of day, making those frustrating robotic interactions a relic of the past. There may even be a future state where consumers prefer to speak with an AI agent in some cases because it’s the most expedient way to solve our problems.
Voice AI isn’t just an upgrade to software’s UI; it’s transforming how businesses and customers connect. The convergence of speech-native AI models and multimodal capabilities has positioned voice AI to transform industries where human communication is critical. We believe investing in voice AI will unlock a new era of business communications, allowing companies to meet rising customer expectations while scaling their operations more efficiently.
If you prefer to listen to the top insights from this roadmap, here is an AI-generated podcast via NotebookLM.
The massive market for voice
Humans like to talk. We speak extensively, making tens of billions of phone calls each day. And despite the prevalence of other communication forms like texting, emailing, and social media, phone calls remain the dominant mode of communication for most businesses. Across industries such as healthcare, legal services, home services, insurance, logistics, and others, businesses rely on phone-based communication to convey complex information more effectively, provide personalized services or advice, handle high-value transactions, and address urgent, time-sensitive needs.
Yet a vast majority of calls go unanswered. For instance, SMBs miss 62% of their calls on average, missing out on addressing customer needs and winning more business. There are multiple inefficiencies with the status quo; calls are sent to voicemail after working hours, humans can only handle one call at a time, and the quality of support is inconsistent — leading to long wait times, after-hours delays, and poor customer experience. Despite pouring money into larger call centers or legacy automation systems, companies struggle to overcome these fundamental constraints.
Previous attempts to integrate technology that could augment phone-based work have seen lackluster success. Returning to our example of calling the airlines, customers often need help navigating through an outdated Interactive Voice Response (IVR) system, a technology that dates back to the 1970s. IVR is when automated systems say things such as, “Press 1 for rebooking” or “In a few words, tell me what you are calling about.” This outdated technology was first designed to automate call handling. Still, it’s built on a rigid system that can only process pre-set commands and cannot truly understand the intent or urgency behind a call. There is no shortage of demand for better voice automation technologies. However, businesses are limited by the technical capabilities to deliver voice products in a way that solves customers’ problems efficiently and pleasantly.
Why now is the time to build in voice
To better impart why now is such an important inflection point for voice-as-an-interface, we’ll reflect on the evolution of voice technology. First, there were IVR systems, as described above, which enterprises and consumers almost universally dislike despite IVR still representing over a $5 billion market today.
Improvements led to the second wave of innovation in voice, as Automatic Speech Recognition (ASR) software, also known as Speech-to-Text (STT) models, focused on transcription, enabling machines to convert spoken language into text in real-time. As ASR approached human-level performance over the past decade, we saw several new companies emerge building on top of ASR, including Gong and our portfolio companies Rev and DeepL. Advancements in ASR/STT have continued with the release of OpenAI’s open-source Whisper model in late 2022 and Rev's 2024 open-source release of Reverb; these types of models have helped power more natural conversational systems capable of processing natural speech rather than rigid menu selections. With these improvements, ASR can better handle accents, background noise, and provide a nuanced understanding of tone, humor, emotion, etc.
In the past year, the voice AI landscape has seen a surge of transformative advancements across research, infrastructure, and application layers. Rapid progress has stemmed from generative voice, with companies like Eleven Labs and others redefining Text-To-Speech (TTS) technology, creating models that produce voices with unprecedented emotional nuance, making AI sound more human than ever before. Google’s launch of Gemini 1.5 brought multimodal search into the fold, combining voice, text, and visual inputs to create a richer user experience. Shortly after that, OpenAI’s Voice Engine further pushed the boundaries of voice recognition, generating speech that closely mimicked natural conversation. The most significant breakthrough, however, came with the unveiling of GPT-4o, a model capable of real-time reasoning natively across audio, vision, and text. This represents a monumental leap forward, showcasing how AI can understand and process human speech and respond with depth and intelligence across multiple modalities.
These innovations are leading to two main developments:
First, a growing array of high-quality models have emerged to support the conversational voice stack, which has led to an influx of developers experimenting with voice applications. Traditionally, voice AI apps have all leveraged a “cascading” architecture: a user’s speech is first transcribed into text using an STT model, then the text is processed by large language models (LLMs) to generate a response, which is finally converted back into speech by a TTS model. However, the cascading nature of this architecture presents two significant drawbacks: latency and the loss of non-textual context. Latency is one of the biggest drivers of a negative user experience, particularly when it exceeds 1000 ms, as typical human speech has a 200 to 500 milliseconds latency. Within the past year, models like GPT-4 Turbo were released, substantially reducing latency. However, it still took developers a lot of engineering to optimize their apps to get closer to human-level latency. In this context, emotional and contextual cues are often lost when converting from audio to text, and these systems struggle with interruptions or overlapping speech due to their rigid, turn-based interaction structure. These technologies — STT, LLMs, and TTS — are rapidly advancing and converging to similar performance levels, which is great news for developers. Certain models perform better on different dimensions, such as latency, expressiveness, and function calling, so developers can pick and choose which models they want to use based on their specific use cases.
Second, we’re seeing groundbreaking progress with the rise of Speech-To-Speech (STS) models, specifically designed to handle speech-based tasks without transcribing audio into text. These models address key limitations in traditional cascading architectures, particularly latency and conversational dynamics. Unlike their predecessors, speech-native models process raw audio inputs and outputs directly, leading to significant improvements:
- Ultra-low latency with response times of ~300 milliseconds, closely mirroring natural human conversational latency.
- Contextual understanding allows these models to retain information from earlier in the conversation, interpret the purpose behind spoken words (even when phrased in varied or complex ways), and identify multiple speakers without losing track of the dialogue.
- Enhanced emotional and tonal awareness, capturing the speaker’s emotions, tone, and sentiment and reflecting those nuances in the model’s responses. This results in more fluid and natural interactions.
- Real-time voice activity detection allows these models to listen to users even while speaking, meaning a user can interrupt them at any time. This is a substantial step forward from cascading applications, which typically rely on rigid turn-taking dynamics where the user has to wait for the agent to finish speaking before it will listen to them. This provides a much more natural and efficient user experience.
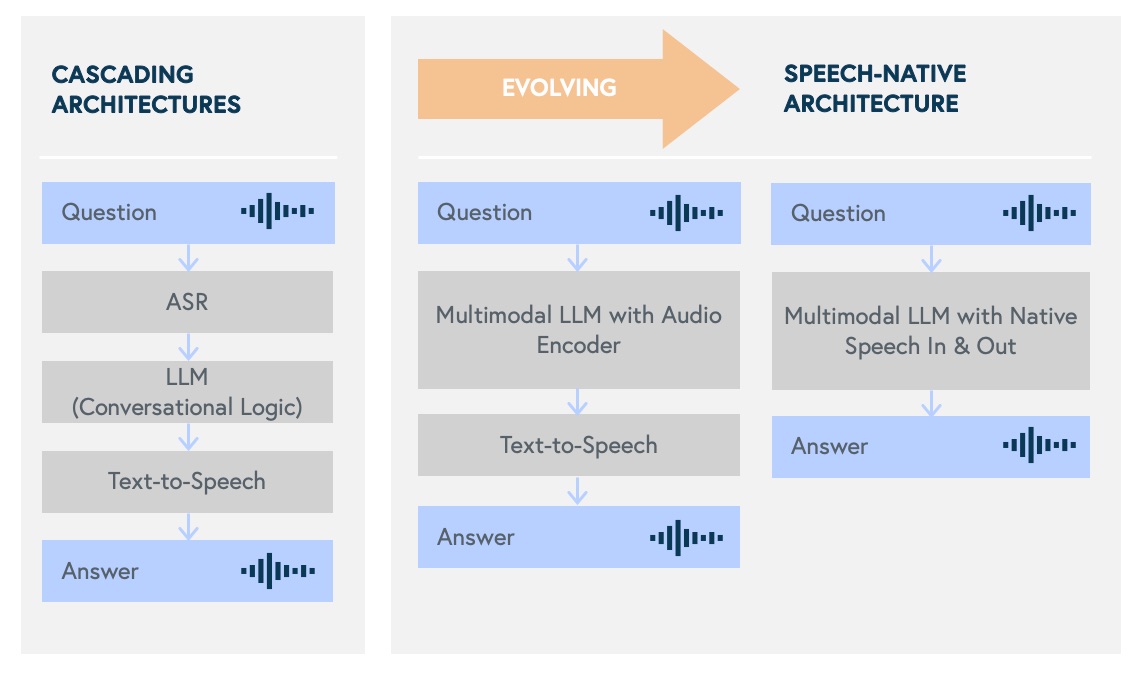
Speech-native models are the future of conversational voice. Alongside OpenAI’s recently released Realtime API, which supports Speech-to-Speech (STS) interactions via GPT-4o, several companies, open-source projects, and research initiatives are advancing the development of this new STS paradigm. Notable examples include Kyutai’s open-source Moshi model, Alibaba’s two open-source foundational speech models, SenseVoice and CosyVoice, and Hume’s voice-to-voice Empathetic Voice Interface, among many others.
Key challenges to industry adoption
Quality, trust, and reliability are the biggest challenges driving enterprise adoption of voice agents. In part, customers are jaded by poor experiences with legacy IVR products, and many modern AI voice agents still need to be more reliable for many use cases or more comprehensive rollouts. Most enterprises start by employing voice agents in low-stakes situations, and as they move to higher-value use cases, the bar becomes very high for agents to perform reliably. For example, a small roofing company might happily employ an agent to field inbound customer calls after hours when they have no alternative. But in a business like this, where each customer call could represent a $30K project, they may be slow to move to a voice agent as the primary answering service as customers may have very little tolerance for an AI agent that fumbles a call and costs them a valuable lead.
Generally, complaints over Voice AI agents can be characterized as performance reliability issues. This includes everything from the call dropping entirely to the agent hallucinating, the latency being too high, and the customer getting frustrated and hanging up. The good news is that voice agents are improving on these dimensions. Developer platforms providing more reliable infrastructure for voice agents are on the rise, focusing on optimizing latency and failing gracefully without interrupting the conversation. Conversational orchestration platforms help give the agent a deterministic flow for them to follow in the conversation, which minimizes hallucinations and provides some guardrails around what the agent is allowed to discuss with customers.
Our Voice AI market map
We’re witnessing innovation at every layer of the stack — from foundational models and core voice infrastructure to developer platforms and verticalized applications. We’re looking to back founders building solutions at every level of the Voice AI stack, and there are several key areas we find particularly exciting:

Models: Under the hood, the foundational model providers build technologies that power various speech-driven use cases. Existing players primarily focus on specific skills — such as SST, LLS, and TTS — designed for cascading architectures. However, it’s clear that the future of voice AI will depend on multimodal or speech-native models that can process audio natively without needing back-and-forth transcription between text and audio. Next-gen voice AI players leverage new architectures and multimodal capabilities to introduce novel approaches. For example, companies like Cartesia are pioneering an entirely new architecture using State Space Models (SSMs). Across the board, we expect significant improvements in foundation models, and we are particularly excited about the development of smaller models that can handle more straightforward conversational turns without relying on the most powerful models. This ability to offload less complex tasks to smaller models will help reduce latency and cost.
Developer Platforms: While the underlying models have significantly improved latency, cost, and context windows, building voice agents and managing real-time voice infrastructure is still a substantial challenge for developers. Thankfully, a category of voice-focused developer platforms has rapidly emerged to help developers abstract away much of the complexity. A few of the core challenges that these developer tools help solve are:
- Optimizing latency and reliability: Maintaining the infrastructure to provide scalable and performant real-time voice agents is a significant burden that would often require an entire engineering team to manage at scale.
- Managing conversational cues, background noise, and non-textual context: Many STT models struggle to determine when a user is done speaking, so developers often need to build their own “end-pointing” detection themselves to address this issue. Additionally, developers often need to enhance the background noise filtering and the sentiment and emotion detection provided by existing models. These seemingly small features can be critical to improving the call quality and bridging the gap between a demo and the higher expectations customers have in production environments.
- Efficient error handling and retries: It is still common for voice model APIs to fail occasionally, bringing a conversation to a screeching halt. The key to building reliable applications on top of this unreliable infrastructure is to quickly identify failed API calls, buy time by inserting filler words in the conversation, and retry the API call to another model, which all needs to be done incredibly quickly.
- Integrations into third-party systems and support for retrieval-augmented generation (RAG): Most business use cases require access to knowledge bases and integrations into third-party systems to provide more intelligent responses and take action on behalf of a user. Doing this in a low-latency fashion that fits naturally into a conversational system is non-trivial.
- Conversational flow control: Flow control allows a developer to specify a deterministic flow of the conversation, giving them far more control than you would get by just providing the model a prompt to guide the conversation. These flow control systems are particularly important in sensitive or regulated conversations like a healthcare call, where a voice agent must confirm the right patient identity before moving on to the next step in a conversation.
- Observability, analytics, and testing: Observability and testing of voice agents are still in their infancy in many ways, and developers are looking for better ways to evaluate their performance both in development and production and, ideally, A/B test multiple agents. In addition, tracking these agents' conversational quality and performance at scale in production remains a significant challenge.
Most developers building a voice agent prefer to focus on creating the business logic and customer experience unique to their product rather than managing the infrastructure and models required to address the mentioned challenges. As a result, many companies have emerged, offering orchestration suites and platforms that simplify the process for developers and/or business users to build, test, deploy, and monitor automated voice agents.
One example is Vapi, which abstracts away the complexity of voice infrastructure and provides the tools to quickly build high-quality, reliable voice agents for enterprises and self-serve customers.
Applications: Finally, companies at the application layer are developing voice-based automation products for a wide range of use cases. We are particularly excited about applications that a) fully “do the work” for customers, handling a complete function end-to-end and delivering valuable outcomes, b) leverage AI’s ability to scale on demand — such as handling thousands of calls simultaneously during peak moments — and c) build highly specialized, vertically-focused solutions with deep integrations into relevant third-party systems. These capabilities allow voice applications to command high ACVs, especially when used in revenue-generating scenarios. Additionally, we’re seeing instances where Voice AI products are creating net new technology budgets in customer segments that typically didn’t spend much on technology, substantially expanding the overall TAM in markets previously considered too small for venture-backed companies.
However, it is also worth noting that quality is a top priority for voice applications. While it's easy to show a compelling demo that gets customers to buy, customers are also quick to churn if a voice agent doesn’t consistently deliver high-quality, reliable service, which is easier said than done. Building a high-quality product requires combining the right models, integrations, conversational flows, and error handling to create an agent that efficiently solves users’ issues without going off the rails. Going the extra mile to build this level of quality is not only key to satisfying customers, but it also helps to enhance product defensibility.
We have identified several functional opportunities for Voice AI at the application layer. These include transcription (e.g., taking notes, suggesting follow-ups based on conversation), inbound calling (e.g., booking appointments, closing warm leads, managing customer success), outbound calling and screening (e.g., sourcing and screening candidates for recruiting, appointment confirmation), training (e.g., single-player mode for sales or interview training), and negotiation (e.g., procurement negotiations, bill disputes, insurance policy negotiations).
We’ve been excited to back some of the first voice AI wave leaders, primarily focused on transcription use cases. This is evident from our investments in Abridge, which documents clinical conversations in healthcare; Rilla, which analyzes and coaches field sales reps in the home services industry; and Rev, which provides best-in-class AI and human-in-the-loop transcription across industries.
Companies expand into fully conversational voice applications across various use cases and industries in this second voice AI wave. One example of an inbound calling solution tailored for a specific industry is Sameday AI, which provides AI sales agents for the home services industry. For instance, when a homeowner calls an HVAC contractor in urgent need of repairs, the AI agent can field the call, provide a quote based on the issue, handle the negotiation, schedule a technician in the customer’s system of record, take payment, and ultimately close what might have been a lost lead.
In the outbound calling space, companies like Wayfaster are automating parts of the interview process for recruiters by integrating with applicant tracking systems to conduct initial screening calls automatically. This allows recruiters to screen hundreds of candidates in a fraction of the time it would take a human team to do so and focus more of their energy on closing the top candidates.
Voice agents are also becoming capable of handling complex tasks across multiple modalities. For example, some companies are helping medical offices use voice agents to negotiate insurance coverage with carriers, leveraging LLMs to sift through thousands of insurance documents and patient records and utilizing those findings for real-time negotiations with insurance agents.
Our principles for investing in Voice AI technologies
As underlying models advance rapidly, the most entrepreneurial opportunities currently sit at the developer platform and application layers. The accelerated pace of model improvements has also enabled entrepreneurs to quickly create effective MVPs, allowing for quick testing and iteration on a product’s value proposition without requiring significant upfront investment. These conditions make it an exciting time to be building in the voice AI ecosystem.
While much of our voice AI thesis aligns with the framework we’ve developed for investing in vertical AI businesses, we wanted to highlight a few key nuances specific to voice solutions. In particular, we emphasize the importance of voice agent quality. It’s easy to develop a compelling demo, but moving from a demo to a production-grade product requires a deep understanding of industry- and customer-specific pain points and the ability to solve a wide range of engineering challenges. Ultimately, we believe that agent quality and execution speed will be the defining factors for success in this category.
Below are our voice AI-specific principles for building in the space:
1. Solutions deeply embedded in industry-specific workflows and across modalities. The most impactful voice AI applications are those deeply embedded within industry-specific workflows. This high level of focus allows companies to tailor their voice agents to the language and types of conversations relevant to the sector, enabling deep integrations with third-party systems, which are essential for agents to take action on a user’s behalf. For example, a voice agent for auto dealerships could integrate with CRMs, leveraging past customer interaction data to improve service and accelerate deployment. Furthermore, applications that combine voice with other modalities add further defensibility by addressing complex, multi-step processes typically reserved for humans.
2. Deliver superior product quality through robust engineering. While building an exciting voice agent demo for a hackathon may be relatively straightforward, the real challenge lies in creating applications that are highly reliable, scalable, and capable of handling a wide range of edge cases. Enterprises require consistent performance, low latency, and seamless integration with existing systems. Founders should focus on designing systems that can handle the unpredictable nature of real-world voice inputs, ensure security, and maintain high uptime. It’s not just about functionality — it’s about building a foundation that guarantees resilience, reliability, and adaptability, distinguishing top-tier voice AI applications from simple prototypes.
3. Balancing growth with retention and product quality KPIs. Voice agents unlock capabilities across revenue-driving functions like sales, and many voice application companies are experiencing rapid and efficient growth as customers look to turbocharge their go-to-market (GTM) functions.
Metrics to measure
Call quality and reliability become increasingly critical as faulty voice agents lead to dissatisfied users who may turn to competitors. Founders should prioritize tracking critical data that reflects product quality, including the following:
- Churn: Churn will be a clear, although lagging, indicator of quality, and we’ve observed that many voice applications have struggled with high churn, particularly in their early days. This is most common in cases where customers shift valuable workflows from a human to an agent that ultimately fails to deliver reliable and consistent user experiences, resulting in customer dissatisfaction.
- Self-Serve Resolution: The higher the self-serve resolution rate, the more effective the voice agent is in fully solving the end user’s problem without human intervention.
- Customer Satisfaction Score: This reflects the overall satisfaction of customers who interact with a voice agent, providing insight into the quality of the experience.
- Call Termination Rates: High call termination rates indicate unsatisfactory user experiences and unresolved issues, signaling that the voice agent may not perform as expected.
- Cohort Call Volume Expansion: This measures whether customers increase their use of a voice agent over time, a key indicator of product value and end-user engagement.
What’s ahead for the future of voice?
Explosive step-function improvements in voice AI models have unlocked exciting startup opportunities across the voice stack in just the past couple of years. As the underlying model and infrastructure technologies in voice keep improving, we expect to see even more products emerge, solving increasingly more complex problems with conversational voice. We’re eager to partner with the most ambitious founders building in this space across all stages.
If you are working on a business in voice AI or want to learn more about how we think about building and investing in these businesses, please don’t hesitate to contact Mike Droesch (mdroesch@bvp.com), Aia Sarycheva (asarycheva@bvp.com), and Libbie Frost (lfrost@bvp.com).