


Vision-native AI opportunities: a precursor to intelligent robotics
Next-gen computer vision models, VLMs, are ushering in ubiquitous physical intelligence.

As AI advances into the real world of robotics and automation, we’re seeing a turning point for physical AI — 1X's NEO Home Robot can now adapt to new environments in real-time, Physical Intelligence's Pi0 became the first robot to fold laundry with human-level dexterity straight from a hamper, and Tesla's Optimus is performing complex warehouse tasks. These significant advances all reflect a fundamental shift in how machines perceive and interact with our physical reality.
The underlying vision models powering these systems have crossed critical thresholds. Vision language models (VLMs) are foundation models that leverage compute, Internet-scale training, and native visual grounding, enabling physical reasoning — not just pattern matching. Recent advances are impressive: Meta's 7-billion-parameter DINOv3 has demonstrated that self-supervised learning can surpass traditional supervised methods for visual backbones. SAM3 can perform zero-shot instance segmentation at impressive quality. These models now work right out of the box: Perceptron's Isaac 0.1 can learn new visual tasks from just a few examples in the prompt, requiring no retraining, and is deployable at the edge with 2 billion parameters.
These implications extend far beyond robotics. Before we get to actuation and physical manipulation, there’s a massive opportunity in vision-native software as the infrastructure that understands the physical world.
Form factor: Capturing the right context
For vision-native products, form factor choice is deeply embedded in the use case. It can create a defensible wedge — such as Flock Safety's purpose-built license plate detectors — but also introduces hardware complexity that pure software avoids. Today's most penetrated form factors remain mobile devices and CCTV cameras, which dominate because they're already deployed at scale. But there's massive surface area for proliferation across existing form factors: smart glasses like Meta Ray-Ban are crossing into mainstream adoption, body cameras are expanding beyond law enforcement into healthcare and utilities, and AR/VR headsets are finding enterprise niches.
The newest opportunity is in mobile visual inspectors, such as quadruped robots from companies like SKILD and ANYbotics that navigate complex industrial environments, climbing stairs, and traversing rough terrain. These will become increasingly common for inspections that are dangerous or impossible for humans. However, the opportunity in stationary systems can’t be overlooked — fixed cameras with enhanced AI can transform passive monitoring into active intelligence across millions of existing installations.
Compute: From edge to cloud
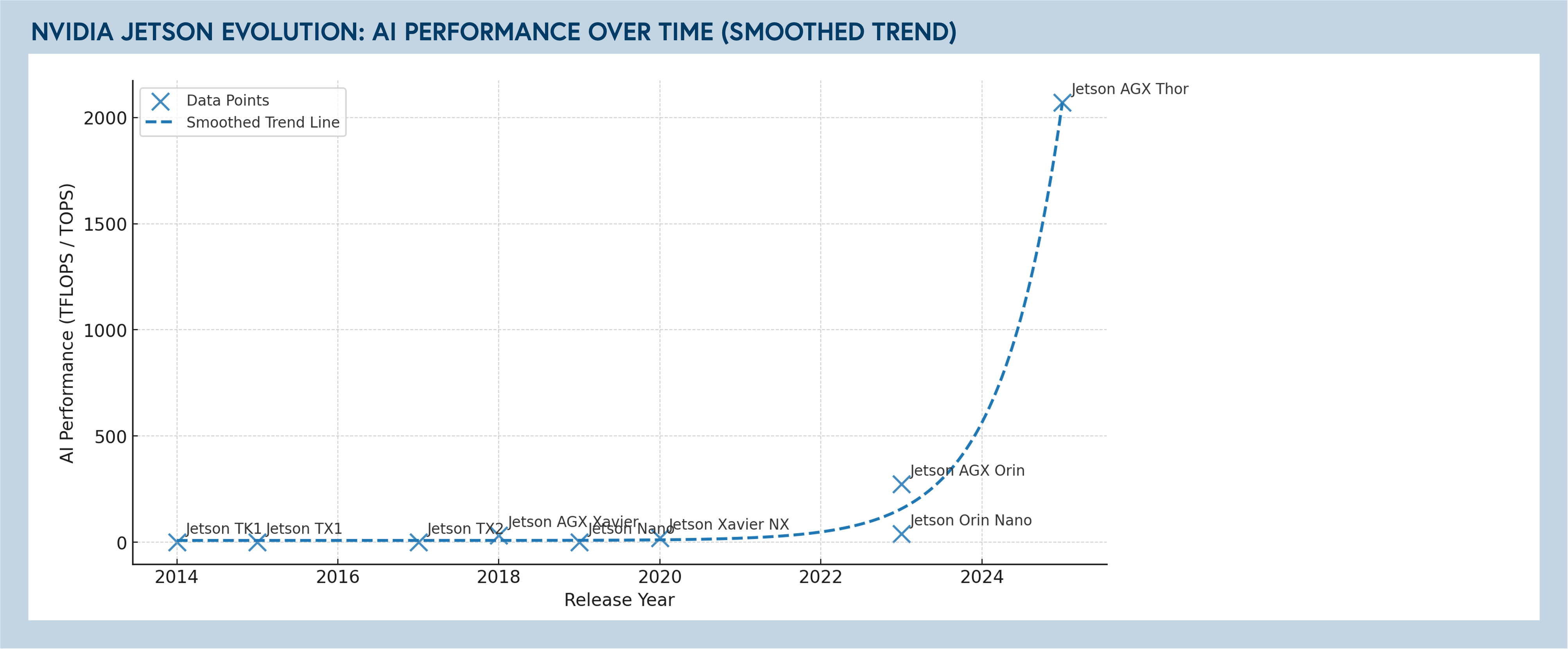
Compute and networking constraints are evolving rapidly as models improve. Small model improvements enable edge processing with mesh networks that send detections and inferences back to the cloud for aggregation. The order-of-magnitude improvements from NVIDIA's Jetson Orin to Thor enable significant low-latency edge-native applications. In domains like CCTV monitoring — where latency matters and network bandwidth historically forced low-resolution compromises — this represents a meaningful breakthrough.
Hybrid architectures are becoming the standard, particularly for vision-language-action (VLA) systems. The canonical example: large vision-language models run in the cloud for complex scene understanding and planning, while lightweight action decoders execute on-device for 50Hz control loops. This split optimizes for both reasoning capability and real-time responsiveness without network dependency.
Cloud-native processing with larger reasoning models, such as Gemini 2.5, Qwen3VL, and GPT-5, continues to show impressive physical reasoning capabilities. But this comes with tradeoffs: cloud dependency, 100ms+ latency, and significant egress/ingress fees that can make continuous operation expensive. The choice isn't just technical, it's economic.
Markets: From document processing to autopilots
Historically, the largest markets for visual AI have been well-defined:
|
Market segment |
Application |
Companies |
|
Document processing |
Extracting structured data from unstructured documents. This market is growing as enterprises digitize operations. |
|
|
Defense applications |
Use of computer vision for surveillance, target identification, and autonomous navigation in contested environments. |
|
|
Security (government and business) |
Intelligent video analytics that move from passive recording to active monitoring for security needs. |
But improved computer vision, SLAM-based localization, and visual proprioception are creating entirely new categories. The key is finding revenue-accretive wedges that directly impact core business KPIs — not just safety and compliance, but productivity and throughput.
The call for vision-native startups
We’re looking for founders building novel experiences that leverage computer vision to enhance real-world processes. What we’re seeing with advanced vision-language(-action) models is a new era of high-impact physical copilots — tools that:
- Directly drive revenue or meaningful cost savings through better visual verification
- Integrate naturally where cameras are already in use, or can be easily added
- Replace manual, error-prone visual workflows with intelligent automation
- Measurably elevate team performance by narrowing gaps between top and average execution
At Bessemer, we’re seeing several categories primed for this infrastructure. Companies building visual copilots, monitoring systems, and optimization tooling that were previously technically or economically unfeasible, will be the necessary foundation for innovating in these areas.
Opportunities for vision-native AI
- Construction: Mobile, bodycam, or drone-based systems for visual quality assurance (QA) on construction progress, safety monitoring, and compliance documentation. A system that can automate progress billing and change order documentation to prevent delays and cost overruns.
- Repair: Between automotives, roofing, construction, and disaster repair, there are opportunities across visual damage assessment, fraud detection, automated decisioning, and report generation.
- Healthcare: For skilled nursing and senior care, the opportunity lies in visual copilots that help the elderly maintain their independence. In hospital operations, there’s operating room turnover monitoring or recording to improve patient flow, billing, patient safety, and health outcomes.
- Field services: For the workforce in the field, there are opportunities to leverage visual intelligence to ensure SOP adherence, maintenance verification, and safety.
- Manufacturing and logistics: Vision copilots can monitor assembly lines, detect defects, and verify process adherence to improve yield and reduce downtime. Systems that use fixed, mobile, or robot-mounted cameras to track work-in-progress, confirm correct labeling and packing, and automate visual QA in warehouses and fulfillment centers.
- Public infrastructure: Vision systems for monitoring roads, public spaces, and utilities to enhance safety and operational efficiency. Vehicle- or drone-mounted cameras that detect hazards such as potholes, debris, or downed power lines, and vision copilots that automate compliance reporting and maintenance prioritization for cities and infrastructure operators.
- Consumer: We see a massive potential in both ecocentric and fixed camera-based assistants for the consumer:
- Kitchen assistants who track food inventory, suggest recipes based on available ingredients, and provide visual cooking guidance
- Home automation that goes beyond voice commands to understand context. Consider an assistant who informs you, "The kids left their bikes in the driveway again."
- Personal organization systems that remember where you put things and can guide you back to them.
We're at an inflection point for vision-native software. Vision models have reached the performance threshold where they can reliably understand and reason with the physical world. The hardware — from smartphones to edge compute — is more affordable and accessible than ever before. The missing piece is applications that translate these capabilities into real value.
If you're building with VLMs or computer vision, we'd love to connect with you. Please reach out to talia@bvp.com or bnagda@bvp.com.


