

What founders need to know to build a high-performing data team
Shopify’s former Head of Data Solmaz Shahalizadeh answers essential questions about hiring, structuring, and measuring the impact of data teams.

Great data teams focus on outcomes, not outputs. Reporting on the performance of the business is just one part of the job. Data teams also need to understand company objectives, and work cross-functionally to help the organization achieve them, using data to uncover problems, propose solutions, identify risks and opportunities, and even build new products.
“A number alone is never the answer for a great data team. It's what we’re going to do as a result of it.” says Solmaz Shahalizadeh, former vice president and head of data at Shopify. Solmaz joined Shopify just before its Series C and helped create a company culture where data informed every decision — decisions that ultimately led to the growth of the platform from 100,000 to over 2 million merchants.
"A number alone is never the answer for a great data team."
During her nine year tenure, Solmaz scaled Shopify’s data organization from a few people to over 500, led the team through a pandemic, recession, and an IPO, and became a trusted partner and advisor to Shopify’s executive team. She and her team also ultimately built Shopify’s suite of machine learning products, including the models that power Shopify Capital, a product that has since distributed over $3 billion in cash advances to merchants.
Solmaz’s deep expertise in data science and her hands-on experience building and leading data teams at scale has made her a sought-out advisor among founders, especially as the rapid advancements in generative AI have created more opportunities (and pressure) for startups to be smarter with data.
To give more founders access to Solmaz’s guidance, we created a two-part series featuring her essential advice on building high-performing data teams. In part one, Solmaz answers the common questions she hears from early-stage founders looking for input on hiring, managing, and setting up data teams for success.
What is a data team and what’s its objective?
Solmaz describes the data team as a “a group of experts that leverage data and relevant technologies such as analytics, statistics, data engineering, and machine learning to impact and grow the product and build new ones.” To Solmaz, that last part — using data to actually impact the business — is the most important part of the data team’s function, and often, the part that gets overlooked or overshadowed by a heavy operational workload.
“The data team doesn’t actually have a different high-level objective from the rest of the company, the go-to-market (GTM) team, or the product team. An effective data team acts as a multiplier, enabling everyone in the company to make better decisions that ultimately lead to successful business outcomes.”
Solmaz gives the example of data teams helping other functions get a birds-eye view of customer needs and behavior in order to improve acquisition and retention. “In the early days of a startup, founders usually speak directly with customers to hear about their experiences. Once the company scales, that becomes impractical, and that’s when you need data to give a voice to customers.”
While the ultimate mandate for the data team is always to use data to improve the performance of business, the methods a team uses, and the sophistication of those methods, will typically evolve alongside the business. Solmaz walks us through three of the key types of data analysis that data teams will eventually need to adopt: descriptive, prescriptive, and predictive.
Descriptive
Just as it sounds, descriptive analysis answers the question: how is the business doing? To be able to report on performance, your early data team (or more likely your first data hire) will need to work with stakeholders to decide which metrics matter most — say, user growth, product adoption, retention.
Then, data teams need to define those metrics in the company’s chosen data stack in a way that makes sense for the business and product, and that everyone will commit to moving forward. Once metrics are defined, Solmaz recommends asking these two questions about each metric, and only investing in the ones that pass the test:
- Do others outside of the data team understand these metrics?
- Is the company actively working to impact these metrics for the better?
“To measure merchant growth at Shopify, we first had to determine who actually counts as a merchant. Is it when they signed up? When they add a credit card for payment? When they actually pay a subscription fee? We wanted to determine that definition up front and get consensus, so that whenever we reported on merchant growth, the next step was to make a plan of action —- not debating metric definitions and calculations.”
Prescriptive
Prescriptive analysis answers the question: What should the business be doing? Descriptive and prescriptive analysis often go hand in hand. Once you’ve defined your key metrics and built out your important reports and dashboards, your data team can move from reporting exclusively on what is happening to helping functions figure out what actions to take based on those findings.
“Data teams become really critical to the company’s success when they can start contextualizing the numbers and making recommendations — basically being able to answer the questions: Why should we care about this metric or its change? What’s the problem we are trying to solve here, and what can we do about it?” explains Solmaz.
“Descriptive analysis is: User acquisition grew by 20% last month. Prescriptive analysis is: We saw 20% growth in user acquisition last month — twice as much as the month before—-because we introduced a new paid channel that is converting really well. Based on the one month retention of these users, we recommend increasing our investment in this channel.”
Predictive
Data teams that are able to run descriptive and prescriptive analysis on product growth and business performance will start using data to predict the potential outcomes of different decisions. They typically also use data to create new features, products, and experiences. That was the case for Solmaz’s team at Shopify.
“You can use data to inform how to build a better product, but you can also integrate data directly into your product experience,” says Solmaz. “At Shopify, we used data that captured browsing patterns, installs, and clicks to identify the marketing apps that our most successful merchants were using, and then we proactively recommended those apps to new merchants.”
Unless you’ve founded an AI company, it likely doesn’t make sense to have your data team invest time and headcount in these types of initiatives until later down the road. However, there’s no question that advancements in LLMs have significantly reduced barriers to experimentation with AI, so if your team has the resources now, it’s always an option.
If you’re already starting to think about how AI could address your company’s unique customer, product, and operational challenges, consider reading the field notes of data leaders at Abridge, Canva, and Zapier who share how their teams incubated, built, and launched products powered by generative AI and language models.
When should you start building a data team?
“There’s no one-size-fits-all rule for when to start building a data team, but it usually makes sense to wait until you have achieved some level of product-market fit and are attempting to scale your growth or GTM motion,” says Solmaz. “Otherwise, your new data hire won’t have enough data to analyze.”
Solmaz recommends applying best practices for data collection early on, even before teams have hired their first data analyst or engineer. “You can start by implementing plug-and-play cloud data storage and transformation tools and use the default setup of these tools. That’s typically all that’s required to collect enough data early on so that your future data hire can get up and running quickly.”
Some technical founders bring on data talent early, but in most cases, the first data role is hired reactively. “You might have a crisis right before a board meeting because the marketing team and the sales team reported different numbers for the same metric or you have brought a new marketing or sales leader that needs data and analytics to be operationally successful. In both scenarios, leadership realizes the team needs to be able to look at business performance consistently and that requires having a data team or at least one person to own it.”
Of course, being intentional about hiring is preferable, and Solmaz has a quick assessment founders can use to decide whether it’s time to start a search. If your answers to all or most questions is yes, it’s likely time to consider bringing on your first individual contributor (IC) focused on data.
- Have you achieved clear product-market fit, or are there early signs of traction?
- Is a significant portion of your organization (at least 25%) focused on GTM?
- Are you investing to scale your growth initiatives?
- Are you currently raising or have you secured Series A funding?
- Are you actively running product or marketing experiments?
For director and VP-level hires to the data team, the assessment looks different. “Again, there is no one-size-fits-all rule, but it usually makes sense to wait until the Series B or C or when the company has reached between $10 million to $20 million of annual recurring revenue (ARR),” says Solmaz.
What are the key roles on the data team?
When hiring for your data team, you’ll likely come across many different titles. As the field of data and machine learning evolves rapidly, so too do the titles. To make it easier to parse, Solmaz gave us an overview of the most common ones and the key distinctions between them:
Data analysts derive insights from datasets, but usually aren’t responsible for creating or cleaning these datasets. A data analyst’s title may vary depending on their focus area. For example, a data analyst may be called a business analyst if their analysis is mostly focused on GTM and operations.
Data scientists use advanced analytics, statistics, and machine learning to predict trends, solve complex problems, and find new ways to ask and answer questions of data. They often possess additional technical skills compared to data analysts, such as the ability to design data pipelines.
Analytics engineers tend to have a mix of business acumen and technical proficiency. They build out a company’s data models and implement data analytics and business intelligence software, so that more teams within the company — especially non-technical ones — can access and benefit from data.
Data platform engineers design and manage a company’s data platform (also called the data tech stack) to give their fellow data experts the foundation they need to thrive.
Machine learning (ML) engineers build machine learning algorithms, systems, and products, from design and development to deployment and iteration.
What are the most important qualities in early data hires?
Individual contributors
These early hires are generalists, this means they have:
- Balance of technical and communication skills: The ideal hire understands the basics of ETL/ELT and data visualizations, but can also share learnings with the leadership in a way that resonates. A person with one but not the other is unlikely to succeed in this role.
- Strong data science background: Advancements in data infrastructure and tools mean you don’t have to hire a data engineer to set up your data pipelines right away. Instead, you can bring on a data scientist (or a data generalist) to do so using existing tools and known best practices, and then have engineering/infrastructure teams manage the tech stack in the short-term.
- Independent and autonomous: Typically, your first data hire will report into the leader of the function that needs data the most (more on this later), so you’ll need an IC who can be successful without the guidance and mentorship of someone with experience in data craft.
- Domain knowledge: As with most hires, it’s always a bonus to bring on candidates who have experience or expertise in your market, business model, product category, or customer profile.
Leaders
- Genuine business interest: Data leaders need to have more than just a passion for their craft — they need to have genuine interest in your market, problem space, and product, and have a point of view on how data can help your company fulfill its mission.
- Practical and hands-on: Early data teams, including data leaders, have to do grunt work that’s essential but not always exciting. Choose someone who not only understands that this will be part of the role at the beginning, but who actually wants to roll up their sleeves and get stuff done.
- Collaborative: The person you hire needs to be able to develop and maintain good working relationships with your CMO, CFO, CTO, and head of product, and deal with conflict if it arises. Data leaders who aren’t effective communicators and problem solvers often don’t prioritize those qualities in candidates, which creates issues that propagate throughout the entire organization and can’t be solved by replacing the person at the top.
One last thing to consider for both roles: if your company is building an AI-powered product, or if you plan to incorporate machine learning into your initial product roadmap, it’s obviously necessary to choose candidates with subject matter expertise in machine learning (engineering and science) in this area for both roles. Otherwise, you can wait to hire these profiles at a later stage.
What’s the best organizational structure for data teams?
How effectively you design your data team’s organizational structure can have a bigger impact on the team’s performance and your company’s use of data in decision-making than almost anything else, including how well you hire and the budget for your data organization and tech stack.
In our conversation, Solmaz walked us through some of the most commonly used organizational structures, as well as their advantages and potential drawbacks.
Organizational structures
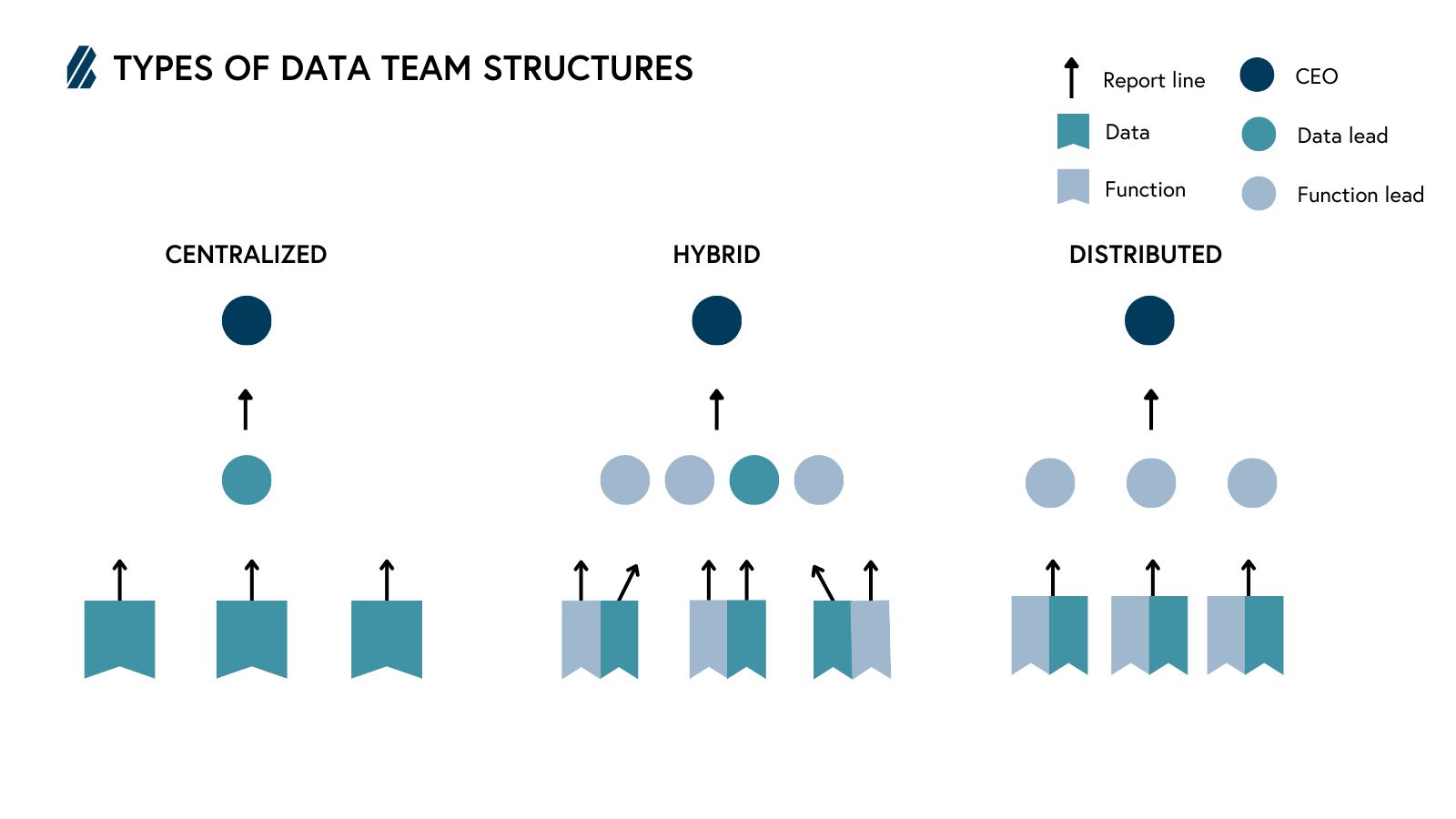
Centralized
In the centralized model, the data team reports into a single data leader who sets strategy and standards for the entire organization. This can help ensure consistency of craft and technical excellence. By working with others in their same function, data team members get ample opportunities to get and give mentorship, share knowledge and best practices, and upskill.
However, when teams scale, the centralized model can start to create inefficiencies and silos. “If the data leader isn’t aware of evolving business priorities, the data team might end up working on solutions to low priority problems,” warns Solmaz. “For instance, the data could spend a quarter trying to reduce fraud, even though fraud isn’t that significant on the platform and the rest of the company is focused on driving user growth.”
When there isn’t close collaboration with other functions, the data team can also run the risk of becoming a service organization, reactively fulfilling requests in isolation. Without the necessary business and product context needed for the prescriptive and predictive analytics, the data team can’t meaningfully impact the business.
This dynamic can happen under any structure, but it’s particularly prevalent among teams using the centralized structure. Solmaz gives an example. “Instead of data scientists working directly with marketers to solve problems and achieve goals, the marketing leader asks the data team, ‘Can we get a report on this?’ The marketing leader will either have to provide context (which they’ve likely repeated already), or they will end up with a report that’s not particularly useful. And even if the data scientist creates a report that makes a big difference, it’s possible they’ll never find that out.”
Distributed
In the distributed model, each of the company’s functions has its own team of data scientists. Those data scientists report into that function's leader (i.e. the VP of Marketing) and work predominantly with other members of the function (i.e. marketers).
Data scientists within a distributed structure develop domain expertise in their function, allowing them to more easily identify and act on problems and opportunities.
For data teams, having the business and product context is essential. As Solmaz puts it, “Innovation comes as a result of knowing the context of the business and product rather than asking obscure questions of the data.”
Like all structures, the distributed model has drawbacks. Data scientists may end up doing the same work twice within different functions, miss out on valuable technical feedback, have different data quality standards and metric definitions than other teams (lowering the impact of their work), and struggle to report objectively on their function’s performance, because the function’s leader is their boss. That last effect causes the most problems. Without agency, data scientists lose their ability to be truth tellers at great cost to the business.
Hybrid
The hybrid model shares many of the advantages of the centralized and distributed models, while reducing the risks of both organizational silos and data anarchy. “In that sense, it’s the best of both worlds,” says Solmaz. “The data team members get to work side by side with functional experts so they have the business context to make an impact, but they also report into a data leader who ensures the excellence of the craft.”
But no model is without compromise. Compared to the distributed structure, hybrid can become slower, with data scientists reporting to a data lead less aware of their day-to-day activities when the team grows. It also requires having more hires compared to centralized structure as people are embedded within a function rather than being shared across multiple.
Still, even with these considerations, Solmaz considers the hybrid model an essential ingredient for Shopify’s success. It was particularly helpful during the COVID-19 pandemic, when many small businesses — Shopify’s bread and butter — were closing up shop.
“When COVID-19 hit, the company had over 10,000 employees, and having data team members embedded into different functions gave us a 360-degree view of the entire business. Every day, a group of data scientists across all domains would get together, and use Shopify data and our collective experience and expertise to get a holistic view of the business."
"We’d ask questions like, ‘How many new merchants are we seeing? Which geographies are they coming from? What are they selling?’ And one of the things we discovered is that merchant growth was increasing much more than we expected in areas that had a severe lockdown, including Spain and Italy. People had lost jobs or were working from home, and had taken the opportunity to start a business.
"Instead of someone just reporting ‘Italy grew by 20%’ in a one-off meeting and deciding to put more marketing spend there, we were able to bring product, GTM, and data into a room and make a collective decision to focus on this user cohort. We ended up offering a free 90-day subscription to merchants during COVID and, as a result, saw an even bigger increase in sign-ups in these geographies.”
Notes on structuring early teams
Your data team will initially be too small to have a data scientist dedicated to each function. “With limited resources, the centralized model is realistically the only option,” says Solmaz. “If you have at least two data scientists, I suggest having one work with engineering and product and the other with GTM and operations so that they don’t have to constantly switch contexts and can review each other's work for quality of analysis. Ideally, the data function grows with the rest of the business and is so impactful that it becomes one of the multipliers of growth in the business.”
In terms of reporting structuring, early data teams will often report to the CEO because they are responsible for overall business success instead of a single department. Alternatively, you may choose to have your early data hires report to the CTO because of the technical aspect of data infrastructure and tooling (the modern tech stack is evolving rapidly, but for initial ideas, check out our data infrastructure roadmap). The other function early data teams may report to is head of Finance (CFO) since Finance is also one of the early functions with high dependency on data and similar level of agency.
What are the hallmarks of a high-performing data team?
While it isn’t always easy to “measure the measurers,” Solmaz has a set of signals that founders can use to assess whether the data team is headed in the right direction or if they need to change course.
Principal among them: “Great data scientists join peers in other functions as decision-makers and always communicate in a language that the business understands,” says Solmaz. “They continue their analysis and input past any number to answer the all-important follow-up question: ‘So, what are we going to do as a result of the analysis?’”
In addition to these essential skills, Solmaz encourages startup leaders to look out for these green and red flags for data teams:
Red flags
- The data team works in a silo, completing one-off requests for individual functions without understanding the high-level needs or objectives that are driving them.
- Data teams focus more on the “what” rather than the “why” of their work. For example: when asked about the impact they’ve had, data team members mostly reference the number of reports and dashboards built or operational improvements made. Or, in conversations within the data team, people focus more on the type of analysis they perform than the business problems they’re trying to solve with it.
- Leaders invite members of the data team to meetings only after decisions are final or close to final, and are asked to provide data that support those decisions, rather than involving data team members through the process and relying on their help to determine the right metrics for a decision.
Green flags
- Individuals on the data team can confidently speak to the company’s overall business priorities as well as the specific objectives and context of the functions they work with the most.
- A senior member of the data team is present in conversations with leadership not only to report on business performance but to discuss priorities, planning, and strategy. This could be a senior IC, director, or VP depending on your stage.
- There are many examples of instances where someone in the company decided to make a different decision based on what the data showed. This happens regularly with small and high-stakes decisions.
- When asked for feedback, functional leaders speak highly of the data team and can clearly articulate the impact of their work.
What else do data leaders need to know?
In part two of this series, Solmaz shares more essential wisdom to help startup leaders with everything from laying the foundation for a high-impact data team to scaling an organization that can effectively build products with machine learning and AI. Plus, she’ll answer key founder questions including how to build out your initial data infrastructure and use data to identify new growth levers for your business.


