
 Bhavik Nagda
Bhavik Nagda
The evolution of machine learning infrastructure
The toolkit and infrastructure empowering machine learning practitioners is advancing as ML adoption accelerates.

The history of machine learning (ML) is short yet storied: the earliest perceptron was invented in the 1950s. Multi-layer networks emerged in the ‘60s, backpropagation came to the fore in the ‘80s, and MNIST in the ‘90s. The new millennium saw the earliest Torch release in 2002, ImageNet in 2009, and AlphaGo in 2016.
For much of that history, most ML advancements were only accessible to research communities. Today, these advancements hold the promise of ubiquitous predictive power when applied to our homes, our phones, and even our blood health. Yet the potential still remains untapped—for years, ML adoption was sluggish and companies struggled to scale even simple prototypes into performant systems.
The industry at large is in its earliest stages, but we’re starting to see signs of material adoption. The crystallization of the toolchain is making ML accessible and scalable. This, in tandem with the rise of modern, cloud-based data infrastructure has accelerated adoption in the industry. There is no better example of this shift than the growth of graphics processing unit (GPU) computing for deep learning. As the market leader in GPU design, Nvidia has a front-row seat to advancements in the ML stack. Over the last couple of years, the spike in its data center revenues—notably, at the height of the pandemic—suggests that cloud ML workloads are growing.
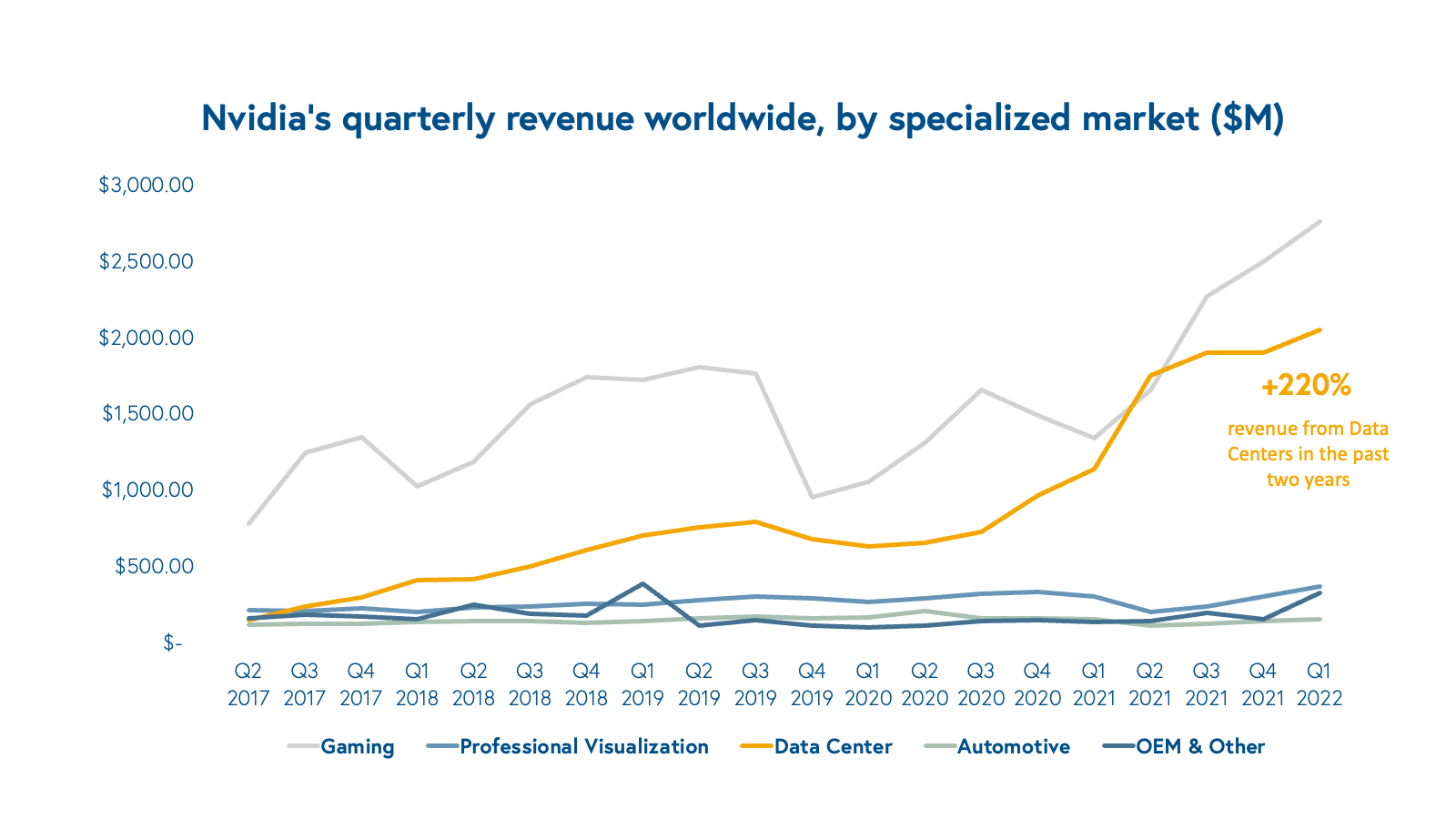
It’s an exciting time to be part of the ML community. Budgets for data and ML are hitting all-time highs, with lots of value to be created across the space. Based on our research and conversations with experts in the industry, we provide an overview of the market accelerants driving innovation in machine learning and explore the emerging themes we’re seeing across the ecosystem, for both application and infra-layer tooling.
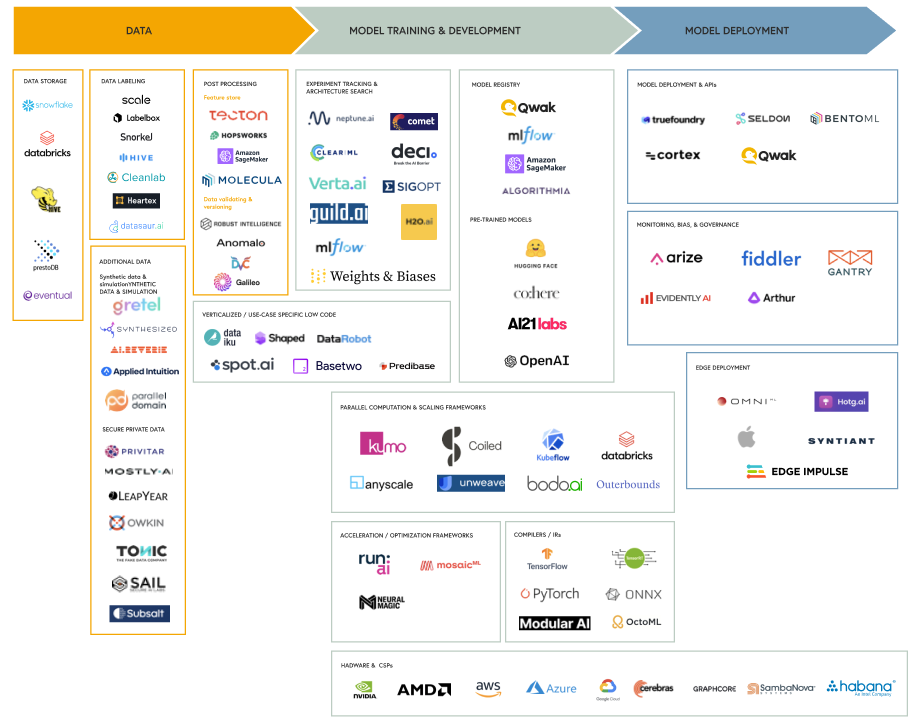
Market accelerants
Maturity in enterprise data strategy
The last decade has seen an acceleration in the creation, capture, and storage of data. Integral to this trend is the emerging emphasis across the business world on data as a lever for growth. Company leaders have been eager to glean valuable insights and drive superior user experiences from data. The software facilitating this data capture has emerged as its own category: data infrastructure.
In the database world, workflow-specific solutions have emerged to optimize for specific types of applications. Engineers have a wider array of tools at their disposal, supporting both event-based (transactional) and business intelligence (analytical) workloads, high-latency complex processing in batch or real-time streaming, and various forms of communication, such as pub-sub brokered messaging or RPC.
Businesses continue to adopt solutions that allow them to meaningfully consume and manipulate data in the cloud. The growth of ELT (extract, load, transform) solutions alongside the traditional ETL paradigm has allowed data engineers to maintain processing pipelines even as the upstream data sources, or data schemas, change. Abstracting away the complexity of data engineering, unified data warehousing solutions have seen rapid adoption to centralize and aggregate company data. (Look no further than the rise of Databricks and Snowflake.) Many of these vendors have sought to decouple the storage of data (storage) from the processing of data (compute), creating flexibility across both layers to support application latency and bandwidth constraints. Above all, perhaps, these technologies are often deployed in the cloud, unlocking an array of collaborative use cases. The emergence and, importantly, adoption of this ecosystem means that for ML engineering and research teams, data is more accessible than ever before.
Today, data strategies across the enterprise are maturing in sophistication, cloud-native IT adoption, and governance. Executives understand they’re sitting on treasure troves of data. Organizationally, companies are building out data teams and hiring scores of data scientists and data engineers. These practitioners are also more nimble as they move past the prior burdens of evolving data schemas, ETL maintenance, and fire fighting. As data tooling improves and standardizes, software teams have more bandwidth to devote to intensive yet value-add ML projects.
Accelerated and edge-optimized hardware
Despite the end of Moore’s law and Denard scaling, processing power continues to accelerate. Advanced hardware architectures—ironically some inspired by ML itself—are accelerating compute capabilities across data modalities. Specialized architectures boast improved performance on specific use cases: GPUs, for example, have become the de facto hardware for vision. Programmable and power-efficient field programmable gate arrays (FPGAs) are becoming popular too, both for chip prototyping (like Tesla’s D1 Dojo Chip prototype) and custom use cases.
Engaging with specialized machine learning hardware is becoming increasingly accessible. A mosaic of low-level software tools for ML and embedded systems engineers is empowering companies to harness these hardware improvements. OpenAI’s Triton library, for example, supplants compute unified device architecture (CUDA) and offers highly-efficient GPU programming. For mass production, chip designers also have an application-specific integrated circuit (ASICs) and associated hardware design languages (HDLs) like Verilog at their disposal. These improvements have indeed helped support the rapid exponential growth in computing necessary to train today’s models—a staggering 300,000x since 2012.
The near-ubiquity of computing power with iPhones and smartphones has accelerated investments in hardware; many of these devices are as powerful as some laptops. The innovation is unlocking a myriad of edge workloads for ML, with material implications across verticals: web3, AR/VR, AgTech, and health sciences, among others.
Although a large fraction of mobile inference still runs on CPUs, recent advances in ML power efficiency and memory usage are making mobile GPU inference a reality. Backed by Big Tech (consider TensorFlow Lite from Google or CoreML from Apple), TinyML is enabling a new class of low-latency, high-bandwidth applications. Researchers studying TinyML have found ways to reduce model sizes, often through model architecture search, computing with lower precision parameters (quantization), removing low-utility weights (pruning), or weight compression schemes. The result is that ML models are finding yet another home in small, low-powered embedded devices.
Accessible and generic model architectures
Although innovation across the ML ecosystem remains diverse and experimental, we’ve witnessed tremendous directional progress over the last two years. The widespread success of large models trained on expansive datasets—foundational models—has unlocked high performance across ML modalities. The coalescence of these foundational models (e.g. BERT, CLIP, the GPTs) has democratized access to high-quality, generic architectures.
Just five years ago, data scientists spent time building bespoke models and modifying hyperparameters. Today, the fine-tuning of foundational models can lead to high performance for downstream tasks. Others employ AutoML tools that automate the discovery and engineering process for ML algorithms—while traditional hyperparameter tuning tools like auto-sklearn or Ray’s Tune have been around for a while, efforts in architecture search and learned optimizers are relatively new and showing promising results.
For the broader ML community, the emergence of foundational models creates network effects—improvements to one model can often flow into its fine-tuned or derived models. The homogenization of models and growing AutoML paradigms also allow for some degree of standardization in the ML stack and process, which enables adoption and further innovation.
That said, there’s a lot of fundamental architectural innovation still necessary in the ecosystem. Mainstream models learn far slower than the average human does, and at Bessemer, we’re closely following the emerging few-shot or zero-shot models that generalize to new tasks with little to no task-specific data. Newer use cases and model types have shown tremendous possibilities too: generative models, multi-modal architectures, and graphical models, among others.
Despite these advancements, large companies building and serving foundational models are experiencing conflicting economics: aggregate costs are racking up as model complexity and data volumes rise. As the team at AI21 points out, the cost of an ML operation (typically a floating point operation, or FLOP) is dropping dramatically, but the costs for training state-of-the-art models are accelerating. Models have scaled faster than the associated drop in computational costs; our ability to leverage more data, build bigger models, and parallelize training across GPUs has accelerated faster than cost reductions in hardware.
There is still massive greenspace to expand ML capabilities.
The numbers and price tags can be dizzying at times. Deepmind allegedly spent $35 million training AlphaGo, and OpenAI spent $12 million for a single GPT-3 training run. Cloud computing is often the single largest line item after labor for software companies. Cloud service providers (such as AWS, Azure, and GCP) earn the lion’s share of cloud spend here, and Nvidia enjoys its leg up with CUDA and its associated GPU chipsets. While the scale of these businesses can be hard to reckon with, there is still massive greenspace to expand ML capabilities—new modalities, applied ML, dev tooling—and reduce engineering constraints like cost, training time, and inference latency.
Trends in the ML stack
The tools involved in orchestrating ML across data processing, training, and inference orchestration have traditionally been sparse and complex. Many early companies chose to build this orchestration layer in-house. Examples here include Facebook’s FBLearner workflow ecosystem, Netflix’s Metaflow infra stack, Uber’s Michaelangelo platform, and Airbnb’s Bighead system.
As broader commercial interest in machine learning has grown, independent vendors have emerged to fill the void, often biting off a piece of the machine learning stack and integrating with emerging best-of-breed technologies or open-source projects. Unsurprisingly, many of the earliest founders here felt the pains natively in their previous roles. The founders of the feature store company Tecton, for example, helped build Michaelangelo at Uber. Outerbounds, another human-centric ML infra company, was founded out of the Metaflow project at Netflix.
In the coming months, we imagine that the space will evolve considerably as companies iterate closely with ML practitioners to address pain points. Below, we describe a few of the key themes we’ve been noticing and a subset of associated landscape players.
Clever data techniques
As ML architectures standardize, data remains a key differentiator and often an economic moat for companies. Much of the industry today operates within supervised domains, which require labels for training data (e.g. semantic segmentation for autonomous vehicles, sentiment analysis in healthcare). In striving for better accuracy, companies must tame the ‘long tail’ of edge cases, which requires volumes of labeled data and meaningful training signals. As a result, human labeling—powered by companies like Scale AI and Labelbox—is an important and often expensive step in bootstrapping models.
Models are often only as strong as the training data they leverage. These days, ML practitioners frequently use a wide array of strategies to increase the amount of training data available. For example, self-supervised learning, which avoids human labeling by using the data and its underlying structure as labels, has seen significant progress in natural language and vision domains. In domains where human labeling is needed, active learning or query learning has shown success in programmatically sampling data to send for annotation—by prioritizing and selecting subsets of data to annotate, companies can avoid labeling lower-lift data. In some cases, easily available and noisy data can be used with imprecise functional rules to label large volumes of data, a technique known as programmatic weak supervision, pioneered by the creators of Snorkel. This technique hinges on labeling functions that programmatically provide often noisy “weak” labels. The pace of innovation and research in the labeling space has been humbling. As data volumes increase, we’re excited to see labeling paradigms evolve as practitioners find innovative business models or research approaches to cheaply acquire labeled data.
Simulation is another approach of infusing physical priors in data distributions, albeit with challenges of its own. Simulation is particularly applicable in robotics, where the cost of acquiring real world data is high and traditional deep reinforcement learning algorithms suffer from sample inefficiency, requiring large amounts of data to train robust models. To accelerate training, roboticists often train models in simulation alongside their real-world deployments. Yet simulators are often bottlenecked by a reality gap between the simulated and real world: the Sim2Real transfer gap. This is often a symptom of parameter gaps (poor tuning) or modeling inefficiencies.
For instance, MuJoCo, a simulator recently acquired and open-sourced by DeepMind, efficiently captures and identifies contacting objects, treating them as non-deformable, or rigid-body objects (thus a rigid-body simulator). In many cases, objects are deformable in some fashion; as MuJoCo has grown in popularity with its efficiency, richness, and now open-source accessibility, many roboticists have resorted to other techniques to overcome the Sim2Real transfer gap. Covariant and NVIDIA, for example, randomize the dynamics of simulated environments (across object types and physics parameters, for example), a technique known as domain randomization. We’re excited about these emerging techniques and the associated performance boost from models leveraging simulated data.
Certain environments or regimes lend themselves to particular data strategies. In high-security or low-trust environments such as banking or healthcare, data is well-guarded and traditionally inaccessible. Inspired by groundbreaking research, companies are finding meaningful workarounds. For example, Doc.ai uses federated learning to train its healthcare models across millions of machines without compromising end-user data.
The synthetic data market is growing in popularity, too. With the improved performance of generative models in the last half-decade, a suite of synthetic data providers has emerged selling both structured (tabular) and unstructured labeled data (usually images and video). These tools are especially powerful in domains where data is difficult to gather, biased, or otherwise noisy. As modern generative technologies (diffusion models, GANs) improve and tooling improves to codify data properties (e.g. entropy, skew) in synthetic data sets, we expect synthetic data adoption to continue accelerating as a means of taming the long tale of ML.
Developer experience
In truth, as a broader industry, we’re still quite early on the infrastructure journey here—there remain growing pains in shipping and maintaining ML at scale. In particular, the lack of tooling makes it difficult to transition away from one-off Python scripts, which are difficult to scale across systems. Troubleshooting and diagnosing model issues are painful, and model drift remains a challenge, perhaps exacerbated post-pandemic.
The operational and collaborative challenges are also quite salient. At many tech companies, large and small, the interface between ML researchers and ML engineers is often frayed and difficult. Operationalizing ML also requires standing up a team to actively monitor model deployments and diagnose customer issues, which is tough for smaller startups.
The last decade has seen considerable maturity in the ML lifecycle. Both infrastructure and application layer tooling has emerged to automate, orchestrate, and help operationalize machine learning. Laying the groundwork for inference at scale, many of these tools offer a broadly-applicable value proposition of:
- Abstracting away complexity for developers
- Templatizing otherwise repetitive infrastructure development
- Building towards a shared, integrated ecosystem empowering developers
The scope of these companies and offerings varies and the ecosystem is fragmented. Many companies support a specific process in the ML lifecycle. Weights & Biases and Comet.ml, for example, offer tooling for experiment tracking and visibility. Seldon offers model deployment and serving, while Outerbounds provides out-of-the-box task orchestration and versioning. Others manage larger swaths of the ML lifecycle: Qwak, for example, offers a full suite of tools with a pitch of a more holistic and integrated product and a consolidated stack for engineers. Basetwo offers a similar stack with no-code model building interfaces for manufacturing process engineers.
As with developer tooling in the past, the open source and research communities are among the many innovators here. We’re excited by this cross-pollination with many prominent ML tools and companies beginning as research or open-source endeavors. Coiled, for example, was founded by the creators of Dask, an open-source project. Anyscale was founded out of Berkeley’s RISELab, and the list goes on.
Risk management and responsible deployment
The vast business value and efficiency gains of ML are no longer news. Yet the ML community has had much to reconcile in the last few years as practitioners have had to confront the ethical and operational risks of ML. Themes like bias, equity, and fairness are of paramount importance not only in research communities and conferences but also in the tech industry, across both the enterprise and startup ecosystems. These risks crop up across the ML lifecycle. Some emerge from poor engineering or accidental underspecification, while others are created by malicious actors.
Many risks are focused on the data itself. As data volumes grow, managing data risk is top of mind; we continue to see enterprises take care in protecting consumer data and avoiding bias in predictive models. We’ve seen growth in tools that help ML practitioners catalog and select data in the hopes of curating diverse training sets.
Models are another risk factor. As companies start to train and deploy models, many are uncovering operational risks and adopting a growing suite of monitoring and visibility tools. For example, the COVID-19 pandemic and associated demographic shifts exacerbated a phenomenon known as model drift—when a shift in data distribution degrades the performance of a model.
Many companies that had trained models pre-pandemic found that as the pandemic wore on, their model performance degraded as consumer demands and demographics shifted. Failure to manage drift can directly impact P&L, as in the case of Zillow, the property marketplace that lost hundreds of millions when its models repeatedly overestimated housing prices as the market cooled early in the pandemic. Model drift is particularly difficult in streaming data regimes, where online models have to adapt dynamically to data changes. Products like Gantry’s evaluation store build towards continual learning, where production systems continually evaluate model performance and retrain models on newer production data.
Finally, we recognize that as with many technologies, ML has the potential for misuse. In the last few years, the research community has identified many attacks that leverage ML or its fragility: adversarial attacks, enhanced side-channel attacks, and password guessing, to name a few. These hacks, like many in years past, pose a threat to society, and we’re emboldened by the entrepreneurs, researchers, and practitioners tackling these issues. In particular, we continue to find companies leveraging ML for security. Case in point: our portfolio company Auth0 uses machine learning and anomaly detection to offer seamless, protected password login across thousands of customers.
We are still in the early days of ML ethics and risk tooling, but we have noticed tremendous innovation and appetite here. At Bessemer, we consider ethical AI deployment to be both a business and a social imperative. We also continue to encounter founders eager to work with policymakers, ethicists, and the broader research community to responsibly deploy their AI technologies.
Fragmentation
Although many model architectures have homogenized, the underlying infrastructure and hardware ecosystem have fractured. In the last few years, research and development across GPU hardware, compilers, and firmware, among other technologies have evolved at breakneck speeds. Empowered by a new generation of tooling for hardware specs and compiler optimizations, researchers have shattered previous ML benchmarks and driven down model training costs.
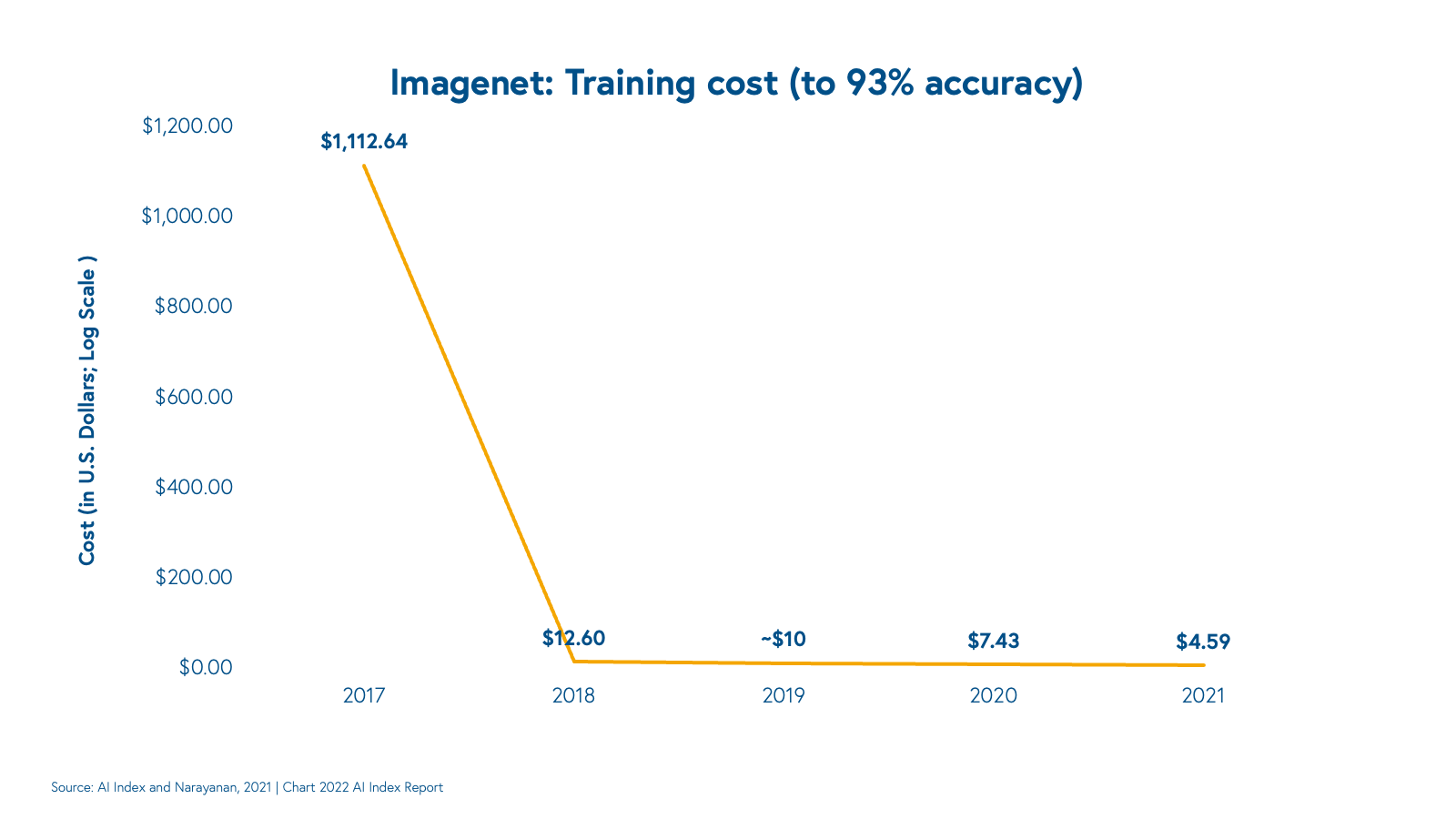
The result, though, has been rapid fragmentation across the stack. Take, for example, the modern execution stack (the ML compiler, runtime, kernels, and associated tooling). Developer-facing ML frameworks (PyTorch, Tensorflow) and associated compilers and intermediate representations (LLVM, XLA, MLIR) evolved independently from hardware and kernel libraries (Intel’s OpenVino, Nvidia’s CUDA, and CuDNN). This means that certain frameworks are compatible only with certain libraries—porting and interoperability remain a pipe dream.
For non-standard targets such as mobile phones or custom ASIC, the challenge compounds. Companies looking to deploy their models across edge and cloud targets are burdened with bespoke integration challenges. As a result, we’re starting to see companies fill the void and unify these technologies. Apache TVM (OctoML) and Modular.ai, for example, are building towards a generic execution framework offering hardware-specific, optimized models.
The industry push to unify these software stacks is often coupled with attempts to optimize them. Across the MLOps pipeline, training remains a priority for optimization. Training workflows, relative to inference, require many more cycles on bare-metal GPU servers. Considering this, bare-metal compute lacks efficiency—many workloads only use 20 or 30 percent of machine resources yet require a lease on the entire GPU. To increase utilization, we’ve seen a few startups emerge, like Run:AI, that dynamically partition GPUs and optimize provisioning and allocation. Startups like Deci.ai, Neural Magic, and OctoML optimize the model itself across multiple vectors like time, cost, and accuracy, applying a variety of intelligent approaches, such as hyperparameter tuning, pruning, sparse regularization, CPU-based parallelism, among others.
Growing opportunities for the machine learning industry
We expect the next few years of ML development to lay the groundwork for the growth of new enterprise ML applications. Today, building a scalable backend for ML involves integrating many tools—a modern stack may include separate vendors for data versioning, labeling, feature stores, model management, monitoring, etc. Provisioning, integrating, and scaling each of these tools requires considerable engineering effort and time, slowing dev velocity. We expect a broader standardization in the de-facto infrastructure stack as model architectures further standardize and turn-key solutions integrate with adjacent vendors in the MLOps lifecycle.
As we work towards a unified vision here, we expect to see traditional software principles—such as modularity, scalability, and reliability—manifest in ML products. The infrastructure tooling will improve the developer experience and build faith in ML systems, accelerating the flywheel of ML adoption.
Indeed, we’re in the early days of what’s shaping up to be a fundamental shift in the way we leverage and scale human intelligence. Yes, ML may very well be a means to an end on our communal quest for near-human intelligence. Yet it is also becoming a cornerstone of the modern enterprise tech stack as companies leverage predictive capabilities to augment their products or decisioning.
At Bessemer, we’re excited about machine learning infrastructure not only because of the technology, but also because of its widespread applications. A robust ML toolchain will empower practitioners across geographies and industries, within small and big companies alike.
We are eager to partner with founders building towards the vision of accessible, responsible machine learning. If you are working on a company building or leveraging machine learning infra, we would love to hear from you! You can contact Bhavik Nagda and Sakib Dadi at datainfra@bvp.com.


